Abstract Syntax Tree (AST) is key concept in program evaluation. It
is a tree with tokens as its nodes. Tree is a better structure than
sequence. Here is why:
Operator precedence.
Hierarchy
Operator precedence
Consider a following expression : 5 + 7 * 2 + 3. It is obvious to us
humans which arithmetic operator. we should calculate first. But it is
not that simple for a machine. Hence, we introduce a tree structure:
Now we need to recursively evaluate each child before calculating the
result of the overall expression.
Hierarchy
Let’s look at the following python code:
def some_method():return1class SomeClass: field =1 other ="other"def class_method(self):returnselfdef other_one(self):return"not classMethod"
Here is a sketch of AST representation:
some_method:
type: function
children:
params: ...
body: ...
SomeClass:
type: class
children:
field:
type: variable
children:
value: ...
other:
type: variable
children:
value: ...
class_method:
type: function
children:
params: ...
body: ...
other_one:
type: function
children:
params: ...
body: ...
Notice how all the functions of class are on the same level. We could
even add fields and functions and
classes nodes to separate statements of different
kinds:
This hierarchical structure is predictable and manageable.
Node structure
AST trees do not have a commonly accepted structure. It’s content
varies depending on usage. But I found some general structure of AST
node. Nodes usually include.
node type (declaration of class, method, variable, infix operator,
block etc)
node value: e.g. name of a particular identifier
children: nodes that a re children of the current one
meta information: position in the initial file, path to initial
file…
To create tokens from code, a tokenizer (aka Lexer) is used. Usually
it’s pretty straightforward: read until next whitespace, identify
obtained token.
To create AST from tokens, we need a parser. I won’t go into much
detail here, because parsers are complicated enough for a separate post.
Some parsers create an intermediate representation of
AST called concrete syntax tree. The difference between AST and CST is
that each AST node has a semantic purpose, while CST may contain
detrimental tokens that are used to make parsing of a grammar work.
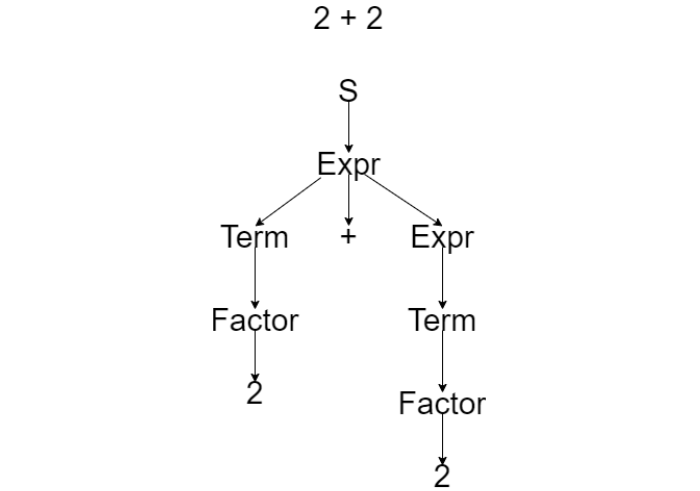
Example of CST generated probably with a parser based on EBNF arithmetic
grammar: Expr,
Term and Factor nodes do not have a semantic
purpose, therefore technically it is not an AST.↩︎